脏页
内存数据页和磁盘数据页不一致时,那么称这个内存数据页为脏页
redo log
存储引擎有一个用来存储物理日志的 redo log 日志文件。在写操作的时候,先将记录写入到 redo log,并更新缓存,然后存储引擎会在适当的时候把操作记录同步到磁盘里。
写 redo log 的过程是顺序写磁盘的,磁盘顺序写减少了寻道等时间,速度比随机写要快很多( 类似 Kafka 存储原理),因此写 redo log 速度是很快的。
为什么会出现脏页
redo log 大小是一定的,且是循环写入的。在高并发场景下,redo log 很快被写满了,但是数据来不及同步到磁盘里,这时候就会产生脏页,并且还会阻塞后续的写入操作。SQL 执行自然会变慢。
什么是读脏页
为了避免每次在读写数据时访问磁盘增加 IO 开销,Innodb 存储引擎通过把相应的数据页和索引页加载到内存的缓冲池(buffer pool)中来提高读写速度。然后按照最近最少使用原则来保留缓冲池中的缓存数据。
那么当要读入的数据页不在内存中时,就需要到缓冲池中申请一个数据页,但缓冲池中数据页是一定的,当数据页达到上限时此时就需要把最久不使用的数据页从内存中淘汰掉。但如果淘汰的是脏页呢,那么就需要把脏页刷到磁盘里才能进行复用。这时,读操作就会变慢。
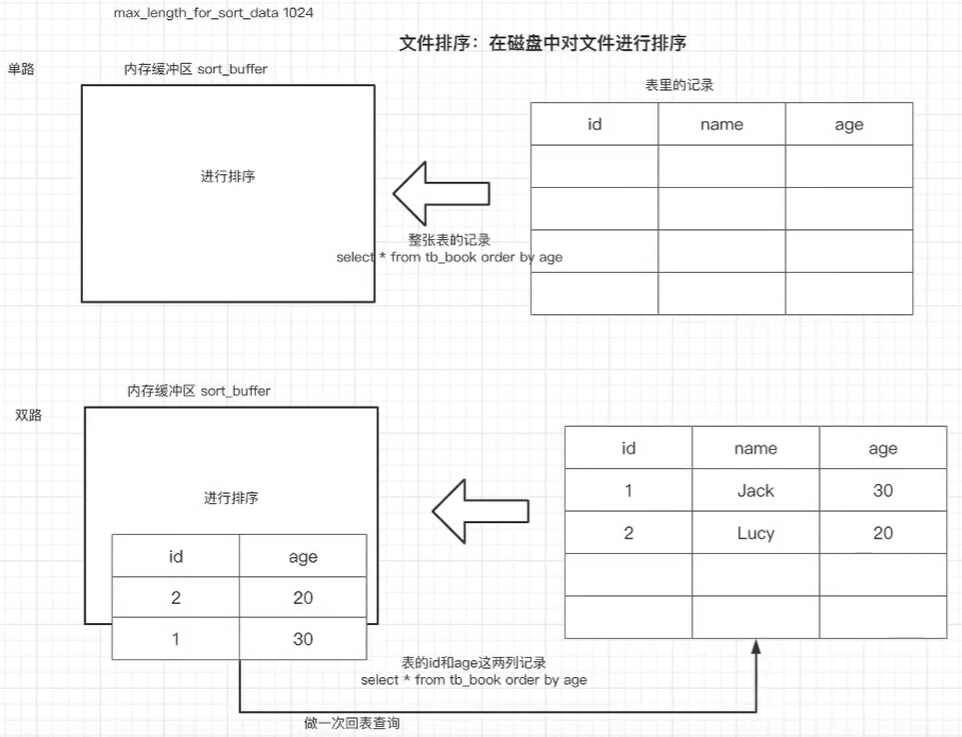
文件排序原理
在执行文件排序的时候,MySQL 会把查询的数据的大小与系统变量 max_length_for_sort_data 的大小进行比较 (默认是 1024 字节) ,如果比系统变量小,那么执行单路排序,反之则执行双路排序
- 单路排序:把所有的数据放到
sort_buffer内存缓冲区中,进行排序,然后返回结果 - 双路排序:取数据的排序字段和主键字段,在内存缓冲区中排序完成后,将主键字段做一次回表查询, 获取完整数据
Order by 优化
- 如果排序的字段创建了联合索引,那么尽量在业务不冲突的情况下,遵循最左前缀法则来写排序语句
- 如果文件排序没办法避免,那么尽量想办法使用覆盖索引(all → index)
Group by 优化
- group by 的原理是先排序后分组,因此对于 group by 的优化参考 order by
分页查询优化
--一次行获取10010,再舍弃掉前10000条
Explain select * from employees limit 10000,10;
--如果在主键连续的情况下,可以使用主键来做条件
Explain select * from employees where id>10000 limit 10;
--如果主键不连续
Explain select * from employees order by name limit 100000,10;
Explain select * from employees a inner join (select id from employees order by name limit 100000,10) b on a.id = b.id;Join 优化
在 join 中会涉及到大表 (数据量大) 和小表 (数据量小) 的概念。MySQL 内部优化器会根据关联字段是否创建了索引,来使用不同的算法。
- nlj(嵌套循环算法):如果关联字段使用了索引,mysql 会对小表做全表扫描,用小表的数据去和大表的数据去做索引字段的关联查询 (type: ref)
- bnlj(块嵌套循环算法):如果关联字段没有使用索引,mysql 会提供一个 join buffer 缓冲区, 先把小表放到缓冲区中,然后全表扫描大表,把大表的数据和缓冲区的小表数据在内存中进行匹配。
结论:使用 join 查询时,一定要建立关联字段的索引,且两张表的关联字段在设计之初就要做到字段类型、长度是一致的, 否则索引会失效。
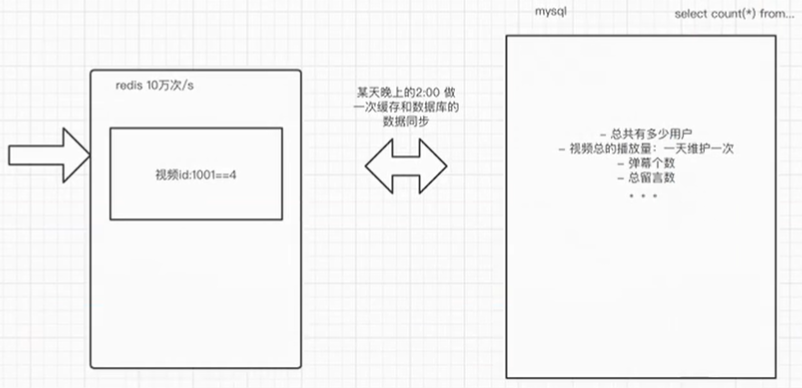
Count 优化
对于 count 的优化应该是架构层面的优化,因为 count 的统计是在一个产品会经常出现,而且每个用户都会访问,所以对于访问频率过高的数据建议维护在缓存中(Redis)