HashMap 的数据结构
我们现在用的是 JDK 1.8,底层是由“数组+链表+红黑树”组成,而在 JDK 1.8 之前是由“数组+链表”组成
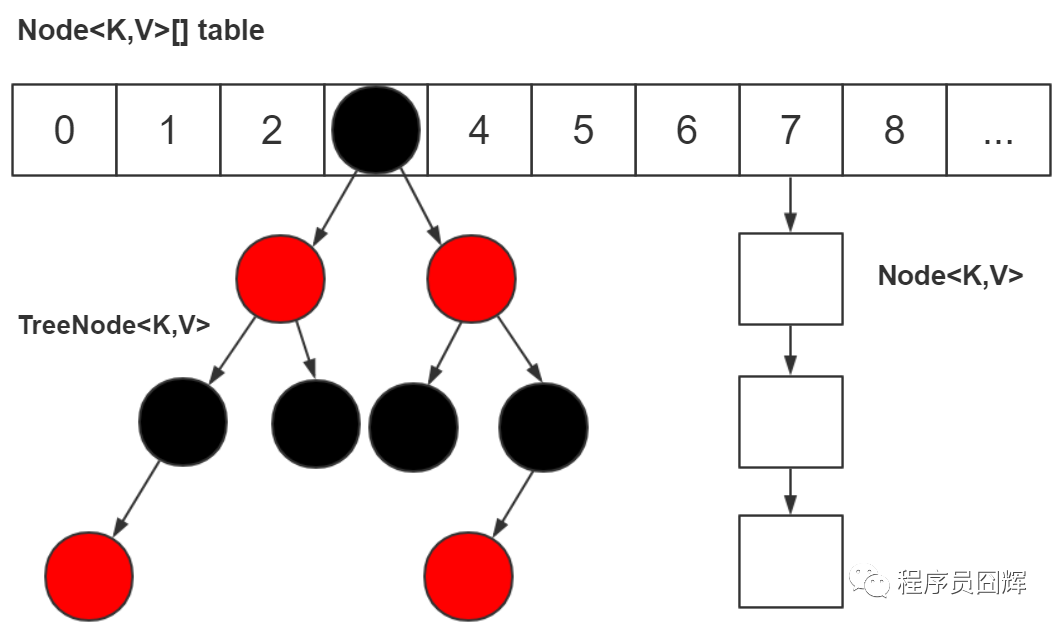
为什么要改成“数组+链表+红黑树”?
为了提升在 hash 冲突严重时(链表过长)的查找性能,使用链表的查找性能是 O(n),而使用红黑树是 O(log n)。
在什么时候用链表?什么时候用红黑树?
对于插入,默认情况下是使用链表节点。当同一个索引位置的节点在新增后超过 8 个,如果此时数组长度大于等于 64,则会触发链表节点转红黑树节点(treeifyBin);而如果数组长度小于 64,则不会触发链表转红黑树,而是会进行扩容,因为此时的数据量还比较小。
对于移除,当同一个索引位置的节点在移除后达到 6 个,并且该索引位置的节点为红黑树节点,会触发红黑树节点转链表节点(untreeify)
为什么链表转红黑树的阈值是 8?
阈值为 8 是在时间和空间上权衡的结果。红黑树节点大小约为链表节点的 2 倍,在节点太少时,红黑树的查找性能优势并不明显。理想情况下,使用随机的哈希码,节点分布在 hash 桶中的频率遵循泊松分布,按照泊松分布的公式计算,链表中节点个数为 8 时的概率为 0.00000006,这个概率足够低了,并且到 8 个节点时,红黑树的性能优势也会开始展现出来,因此 8 是一个较合理的数字。
为什么转回链表节点是用的 6 而不是 8?
如果我们设置节点多于 8 个转红黑树,少于 8 个就马上转链表,当节点个数在 8 徘徊时,就会频繁进行红黑树和链表的转换,造成性能的损耗。
HashMap 有哪些重要属性?分别用于做什么的?
- 用来存储节点 table 数组;
- size:HashMap 已经存储的节点个数;
- loadFactor:负载因子(0.75f),扩容阈值 = 容量 * 负载因子;
- threshold:扩容阈值,当 HashMap 的个数达到该值,触发扩容。
threshold 除了用于存放扩容阈值还有其他作用吗?
在新建 HashMap 对象时, threshold 被用来存初始化数组的容量。HashMap 直到我们第一次插入节点时,才会对数组进行初始化,避免不必要的空间浪费。
HashMap 的默认初始容量是多少?HashMap 的容量有什么限制吗?
默认初始容量是 16。HashMap 的容量必须是 2 的 N 次方,HashMap 会根据我们传入的容量计算一个大于等于该容量的最小的 2 的 N 次方,例如传 9,容量为 16( Java 8 HashMap 之 tableSizeFor )
为什么 HashMap 的容量必须是 2 的 N 次方
核心目的是:实现节点均匀分布,减少 hash 冲突。
计算索引位置的公式为:(n - 1) & hash,当 n 为 2 的 N 次方时,n - 1 为低位全是 1 的值,此时任何值跟 n - 1 进行 & 运算的结果为该值的低 N 位,达到了和取模同样的效果,实现了均匀分布,而且 & 运算比 mod 具有更高的效率。
为什么 HashMap 的默认初始容量是 16,而不是其他?
16 是 2 的 N 次方,并且是一个较合理的大小。实际上,我们在新建 HashMap 时,最好是根据自己使用情况设置初始容量,这才是最合理的方案。
为什么负载因子默认值是 0.75 而不是其他?
这个是在时间和空间上权衡的结果。如果值较高,例如 1,此时会减少空间开销,但是 hash 冲突的概率会增大,增加查找成本;而如果值较低,例如 0.5 ,此时 hash 冲突会降低,但是有一半的空间会被浪费,所以折衷考虑 0.75 是一个合理的值。
HashMap 的插入流程是怎么样的
- 首先对 key 做 hash 运算,然后计算出 key 所在的 index。
- 如果没有哈希冲突,直接放到数组中,如果冲突了,需要判断目前数据结构是链表还是红黑树,根据不同的情况来进行插入。
- 假设 key 是相同的,则替换到原来的值。
- 最后判断哈希表是否满了 (当前容量 * 负载因子),如果满了,则扩容
HashMap 的 get 流程是怎么样的
- 对 key 做 hash 运算,计算出该 key 所在的 index,然后判断是否有 hash 冲突
- 如果没有冲突,直接返回
- 如果有冲突,则判断当前数据结构是链表还是红黑树,分别从不同的数据结构中取出
在 put 元素的时候,传递的 Key 是怎么算哈希值的?
拿到 key 的 hashCode,并将 hashCode 的高 16 位和 hashCode 进行异或(XOR)运算,得到最终的 hash 值。这样做的好处是增加随机性,减少了碰撞冲突的可能性。
为什么要将 hashCode 的高 16 位参与运算?
主要是为了在 table 的长度较小的时候,让高位也参与运算,并且不会有太大的开销。如果不加入高位运算,计算索引值的时候 (n-1)&hash,结果只取决于 hash 值的低 16 位,无论高位怎么变化,结果都是一样的。
HashMap 的扩容流程
- 每次 put 元素进去的时候,都会检查 HashMap 的大小有没有超过扩容阈值,如果有,则需要扩容。
- 创建一个新的数组,其容量为旧数组的两倍,并重新计算旧数组中结点的存储位置。结点在新数组中的位置只有两种,原下标位置或原下标 + 旧数组的大小。
红黑树和链表都是通过 e.hash & oldCap == 0 来定位在新表的索引位置,这是为什么?
扩容前 table 的容量为 16,a 节点和 b 节点在扩容前处于同一索引位置。
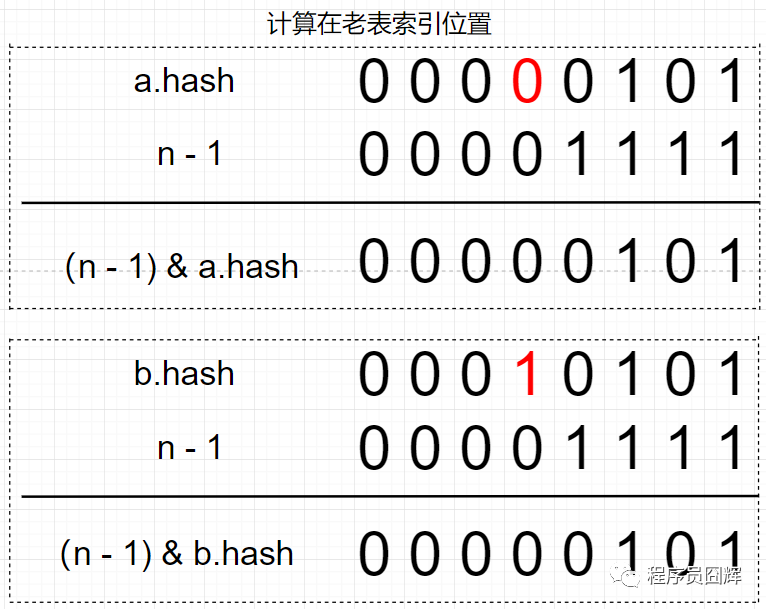
扩容后,table 长度为 32,新表的 n - 1 只比老表的 n - 1 在高位多了一个 1(图中标红)
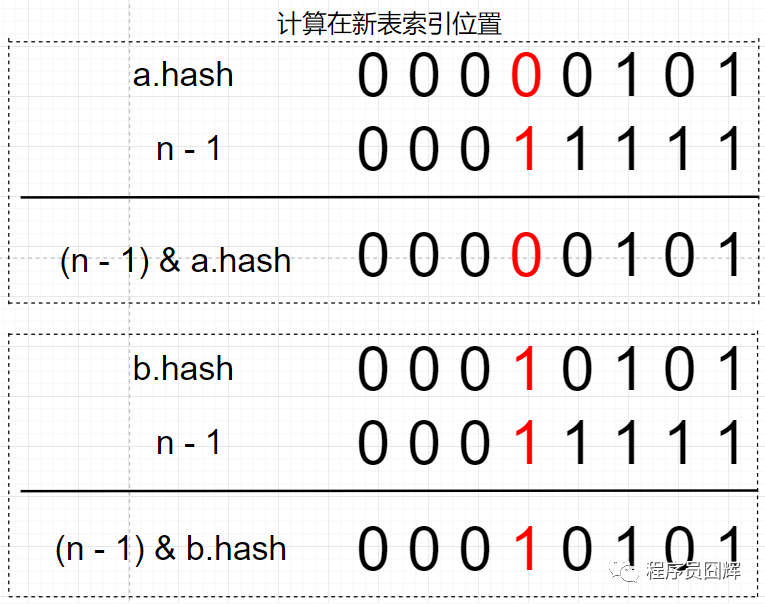
因为 2 个节点在老表是同一个索引位置,因此计算新表的索引位置时,只取决于新表在高位多出来的这一位(图中标红),而这一位的值刚好等于 oldCap。
因为只取决于这一位,所以只会存在两种情况:1) (e.hash & oldCap) == 0 ,则新表索引位置为“原索引位置” ;2)(e.hash & oldCap) != 0,则新表索引位置为“原索引 + oldCap 位置”。
HashMap 是线程安全的吗?
不是。HashMap 在并发下存在数据覆盖、遍历的同时进行修改会抛出 ConcurrentModificationException 异常等问题,JDK 1.8 之前还存在死循环问题。
为什么 HashMap 会产生死循环?
在 JDK 1.8 中 HashMap 主要进行了哪些优化?
- 底层数据结构从“数组+链表”改成“数组+链表+红黑树”,主要是优化了 hash 冲突较严重时,链表过长的查找性能:O(n) → O(logn)。
- 计算 table 初始容量的方式发生了改变,老的方式是从 1 开始不断向左进行移位运算,直到找到大于等于入参容量的值;新的方式则是通过“5 个移位+或等于运算”来计算。
- 优化了 hash 值的计算方式,让高 16 位参与了运算。
- 扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的 死循环 。
- 扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”,性能可能提升不大,但设计更巧妙、更优雅。
为什么要重写 equals 和 hashCode 方法
当我们用 HashMap 存入自定义的类时,如果不重写这个自定义类的 equals 和 hashCode 方法,得到的结果会和我们预期的不一样。如果没有重写 hashCode 方法,我们放入自定义类时,hash 值是根据对象的地址算出来的。如果没有重写 equals 方法,在判断值是否相等时会调用 Object 类的 equals 方法,Object 的固有方法是根据两个对象的内存地址来判断对象是否相等的。
除了 HashMap,还用过哪些 Map,在使用时怎么选择?
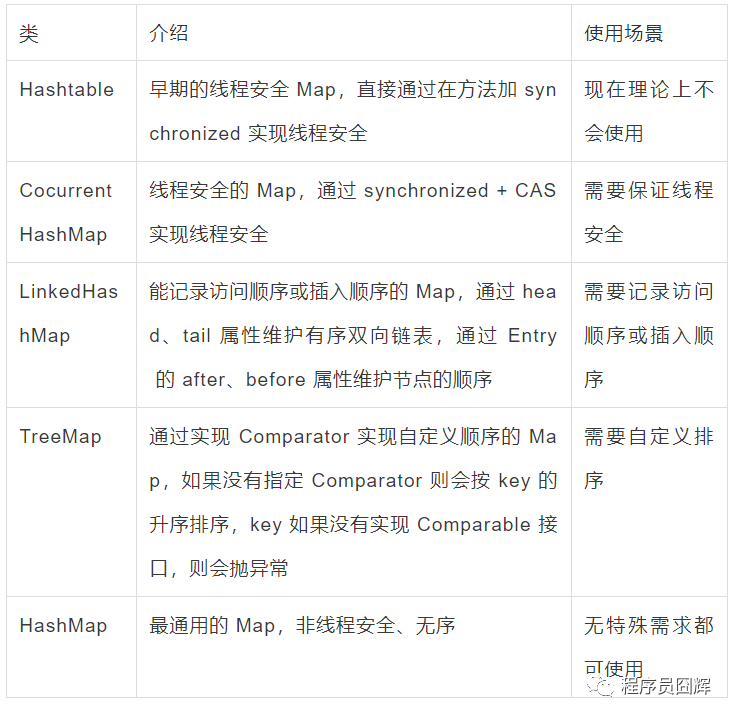
HashMap 和 Hashtable 的区别
- HashMap 允许 key 和 value 为 null,Hashtable 不允许。
- HashMap 的默认初始容量为 16,Hashtable 为 11。
- HashMap 的扩容为原来的 2 倍,Hashtable 的扩容为原来的 2 倍加 1。
- HashMap 是非线程安全的,Hashtable 是线程安全的。
- HashMap 的 hash 值重新计算过,Hashtable 直接使用 hashCode。
- HashMap 去掉了 Hashtable 中的 contains 方法。
- HashMap 继承自 AbstractMap 类,Hashtable 继承自 Dictionary 类。
HashMap 和 ConcurrentHashMap 的区别?
除了加锁,原理上无太大区别。HashMap 的键值对允许有 null,但是 ConCurrentHashMap 都不允许。
为什么 ConcurrentHashMap 比 HashTable 效率要高?
HashTable 使用 synchronized 修饰方法来保证线程安全,每个实例对象只有一把锁,并发性能较低,相当于串行访问;
ConcurrentHashMap 在 JDK 1.7 中使用分段锁( Segment )保证线程安全,每个分段(Segment)包含若干个 HashEntry,当并发访问不同分段的数据时,不会产生锁竞争,从而提升并发性能。
- 不同 Segment 的写入是可以并发执行的。
- 同一 Segment 的写和读是可以并发执行的。
- 同一 Segment 的并发写入是需要上锁的,因此对同一 Segment 的并发写入会被阻塞。
JDK 1.8 使用 synchronized + CAS 的方式保证线程安全,每次只锁一个节点(Node),进一步降低锁粒度,降低锁冲突的概率,从而提升并发性能。
什么是 Segment?
Segment 相当于一个 HashMap 对象。 同 HashMap 一样,Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点。
单一的 Segment 结构如下:
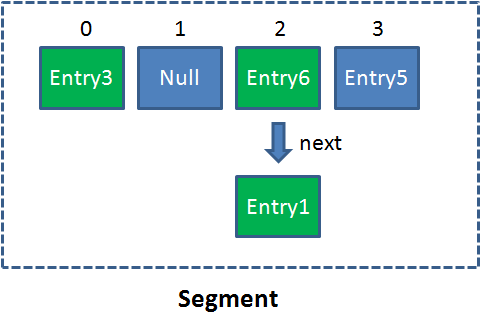
在 ConcurrentHashMap 中有 2 的 N 次方个 Segment,共同保存在一个名为 segments 的数组当中。
因此整个 ConcurrentHashMap 的结构如下:
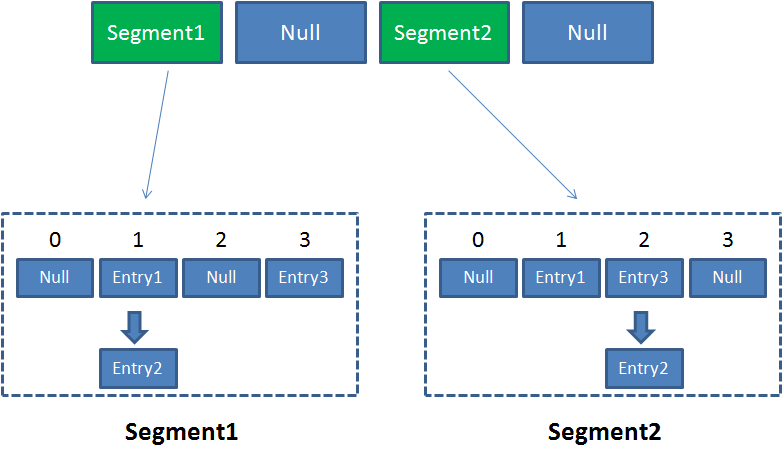
ConCurrentHashMap 在 1.7 和 1.8 区别
数据结构
JDK1.7
- 底层结构:分段的数组+链表;
- 实现线程安全的方式:分段锁(Segment,继承了 ReentrantLock) JDK1.8
- 底层结构为:数组+链表+红黑树;
- 实现线程安全的方式:CAS + Synchronized
- JDK1.8 中降低锁的粒度。JDK1.7 版本锁的粒度是基于 Segment 的,包含多个节点(HashEntry),而 JDK1.8 锁的粒度就是单节点(Node)。
- JDK1.8 使用红黑树来优化链表,跟 HashMap 一样,优化了极端情况下,链表过长带来的性能问题。
- JDK1.8 使用内置锁 synchronized 来代替重入锁 ReentrantLock,synchronized 是官方一直在不断优化的,现在性能已经比较可观,也是官方推荐使用的加锁方式。
put()
JDK1.7 中的实现: ConCurrentHashMap 和 HashMap 的 put() 方法实现基本类似,所以主要讲一下为了实现并发性,ConCurrentHashMap 1.7 有了什么改变
- 需要定位 2 次 (segments[i],segment 中的 table[i])
由于引入 segment 的概念,所以需要
- 先通过 key 的
rehash 值的高位和segments 数组大小-1相与得到在 segments 中的位置 - 然后在通过
key 的 rehash 值和table 数组大小-1相与得到在 table 中的位置
- 先通过 key 的
- 没获取到 segment 锁的线程,没有权力进行 put 操作,不是像 HashTable 一样去挂起等待,而是会去做一下 put 操作前的准备:
- table[i] 的位置 (你的值要 put 到哪个桶中)
- 通过首节点 first 遍历链表找有没有相同 key
- 在进行 1、2 的期间还不断自旋获取锁,超过
64 次线程挂起!
JDK1.8 中的实现:
- 先拿到根据
rehash 值定位,拿到 table[i] 的首节点 first,然后:- 如果为
null,通过CAS的方式把 value put 进去 - 如果
非 null,并且first.hash == -1,说明其他线程在扩容,参与一起扩容 - 如果
非 null,并且first.hash != -1,Synchronized 锁住 first 节点,判断是链表还是红黑树,遍历插入。
- 如果为
get()
JDK1.7 中的实现:
-
由于变量
value是由volatile修饰的,java 内存模型中的happen before规则保证了 对于 volatile 修饰的变量始终是写操作先于读操作的,并且还有 volatile 的内存可见性保证修改完的数据可以马上更新到主存中,所以能保证在并发情况下,读出来的数据是最新的数据。 -
如果 get() 到的是 null 值才去加锁。
JDK1.8 中的实现:
- 和 JDK1.7 类似
resize()
JDK1.7 中的实现:
- 跟 HashMap 的 resize() 没太大区别,都是在 put() 元素时去做的扩容,所以在 1.7 中的实现是获得了锁之后,在单线程中去做扩容(1.
new 个 2 倍数组2.遍历 old 数组节点搬去新数组)。
JDK1.8 中的实现:
- jdk1.8 的扩容支持并发迁移节点,从 old 数组的尾部开始,如果该桶被其他线程处理过了,就创建一个 ForwardingNode 放到该桶的首节点,hash 值为 - 1,其他线程判断 hash 值为 - 1 后就知道该桶被处理过了。
计算 size
JDK1.7 中的实现:
- 先采用不加锁的方式,计算两次,如果两次结果一样,说明是正确的,返回。
- 如果两次结果不一样,则把所有 segment 锁住,重新计算所有 segment 的
Count的和
JDK1.8 中的实现:
由于没有 segment 的概念,所以只需要用一个 baseCount 变量来记录 ConcurrentHashMap 当前节点的个数。
- 先尝试通过 CAS 修改
baseCount - 如果多线程竞争激烈,某些线程 CAS 失败,那就 CAS 尝试将
CELLSBUSY置 1,成功则可以把baseCount 变化的次数暂存到一个数组counterCells里,后续数组counterCells的值会加到baseCount中。 - 如果
CELLSBUSY置 1 失败又会反复进行 CASbaseCount和 CAScounterCells数组
参考链接