什么是 SAGA 事务
SAGA 绝对可以说是历史非常悠久了,SAGA 事务理论在 1987 年 Hector & Kenneth 在 ACM 发表的论文 《Sagas》 中就被提出了,早于分布式事务概念的提出。
SAGA 属于长事务解决方案,其核心思想是将长事务拆分为多个本地短事务(本地短事务序列)。
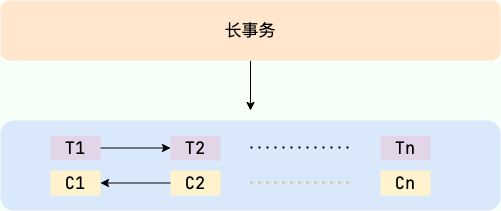
特点:
- 把长事务分解成多个本地短事务 (T1, T2 ~ Tn)
- 每个短事务都有一个补偿动作(C1, C2 ~ Cn)
如果所有本地短事务都能顺利提交的话,整个长事务也就顺利结束,否则,将采取恢复模式。
SAGA 定义了两种恢复策略,反向补偿和正向重试。
反向补偿:
- 如果 Ti 短事务提交失败,则补偿所有已完成的事务(一直执行 Ci 对 Ti 进行补偿)。
- 执行顺序:T1,T2,…,Ti(失败),Ci(补偿),…,C2,C1。
正向重试:
- 如果 Ti 短事务提交失败,则一直对 Ti 进行重试,直至成功为止。
- 执行顺序:T1,T2,…,Ti(失败),Ti(重试)…,Ti+1,…,Tn。
和 TCC 类似,SAGA 正向操作与补偿操作都需要业务开发者自己实现,因此也属于侵入业务代码的一种分布式解决方案。和 TCC 很大的一点不同是 SAGA 没有“Try” 动作,它的本地事务 Ti 直接被提交。因此,性能非常高!
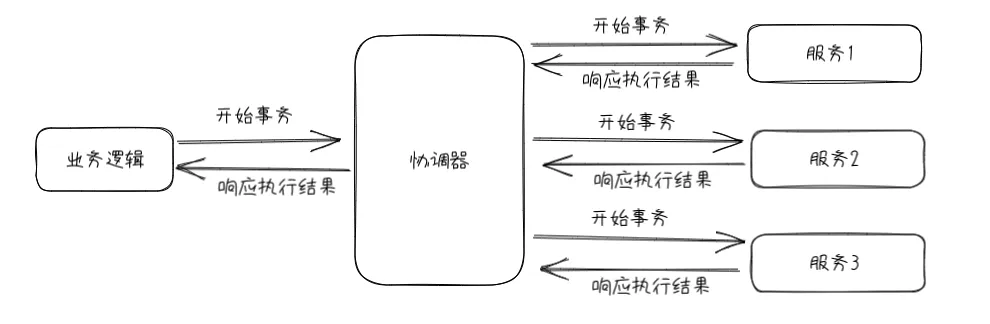
实现方式
- 命令协调 (Order Orchestrator):中央协调器负责集中处理事件的决策和业务逻辑排序。
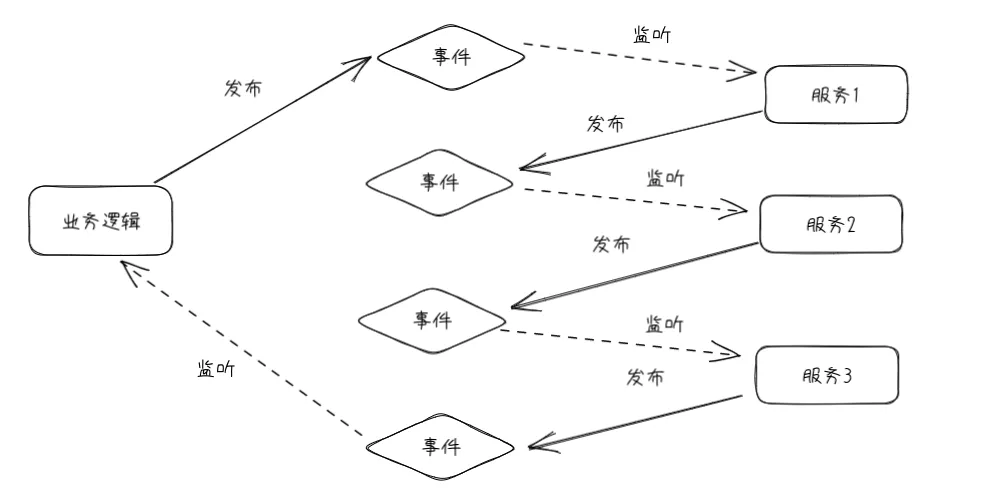
- 事件编排 (Event Choreography):没有中央协调器(没有单点风险)时,每个服务产生并观察其他服务的事件,并决定是否应采取行动。在事件编排方法中,第一个服务执行一个事务,然后发布一个事件。该事件被一个或多个服务进行监听,这些服务再执行本地事务并发布(或不发布)新的事件。当最后一个服务执行本地事务并且不发布任何事件时,意味着分布式事务结束,或者它发布的事件没有被任何 SAGA 参与者听到都意味着事务结束。
优点
- 子事务 (或流程) ,提交是本地事务级别的,没有所谓的全局锁,在长事务流程下,避免了长时间的资源锁定。
- 通过补偿机制,能够从局部故障中恢复,保证系统的稳定性和数据的一致性。
缺点
- 正向重试和补偿服务都由业务开发者实现,所以业务上是有开发成本的。补偿操作本身可能带来额外的资源消耗和延迟。
- 因为一阶段子事务提交是本地事务级别的,所以 SAGA 模式不保证隔离性。提交之后就可能“影响”其他分布式事务、或者被其他分布式事务所“影响”。
- 例如:其他分布式事务读取到了当前未完成分布式事务中子事务的更新,导致脏读;其他分布式事务更新了当前未完成分布式事务子事务更新过的字段,导致当前事务更新丢失;还有不可重复读的场景等。
使用场景
- 长事务流程,业务上难以接受长时间的资源锁定,SAGA 的特性使得它在长事务流程上处理非常容易;
- 业务性质上,可以接受或者解决缺乏隔离性导致的“影响”。例如部分业务只要求最终一致性,对于隔离性要求没有那么严格,其实是可以落地 SAGA 模式的;
- 分布式事务参与者包含其他机构或者三方的服务,数据资源服务不是我们自身维护,无法提供 TCC 模式要求的几个接口。
框架选型
- Seata : 阿里巴巴开源的分布式事务解决方案。
- Hmily :Hmily 是一款高性能,零侵入,金融级分布式事务解决方案,目前主要提供柔性事务的支持,包含 TCC, TAC(自动生成回滚 SQL) 方案,未来还会支持 XA 等方案。个人开发项目,目前在京东数科重启,未来会成为京东数科的分布式事务解决方案。
- Raincat : 2 阶段提交分布式事务中间件。
- Myth : 采用消息队列解决分布式事务的开源框架, 基于 Java 语言来开发(JDK1.8),支持 Dubbo,Spring Cloud,Motan 等 RPC 框架进行分布式事务。
Reference